%load_ext itikzGradient vector
Definition. Let \(f:\mathbf{R}^n \to \mathbf{R}\) be a scalar-valued function. The gradient vector of \(f\) is defined as:
\[\begin{align*} \nabla f(\mathbf{x}) = \left[\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2},\ldots,\frac{\partial f}{\partial x_n}\right] \end{align*}\]
The graph of the function \(f:\mathbf{R}^n \to \mathbf{R}\) is the hypersurface in \(\mathbf{R}^{n+1}\) given by the equation \(x_{n+1}=f(x_1,\ldots,x_n)\).
Definition. \(f\) is said to be differentiable at \(\mathbf{a}\) if all the partial derivatives \(f_{x_i}(\mathbf{a})\) exist and if the function \(h(\mathbf{x})\) defined by:
\[\begin{align*} h(\mathbf{x}) = f(\mathbf{a}) + \nabla f(\mathbf{a})\cdot (\mathbf{x}-\mathbf{a}) \end{align*}\]
is a good linear approximation to \(f\) near \(a\), meaning that:
\[\begin{align*} L = \lim_{\mathbf{x} \to \mathbf{a}} \frac{f(\mathbf{x}) - h(\mathbf{x})}{||\mathbf{x} - \mathbf{a}||} = 0 \end{align*}\]
If \(f\) is differentiable at \(\mathbf{a},f(\mathbf{a})\), then the hypersurface determined by the graph has a tangent hyperplane at \((\mathbf{a},f(\mathbf{a}))\) given by the equation:
\[\begin{align*} h(\mathbf{x}) = f(\mathbf{a}) + \nabla f(\mathbf{a})\cdot (\mathbf{x}-\mathbf{a}) \end{align*}\]
The directional derivative
Let \(f(x,y)\) be a scalar-valued function of two variables. We understand the partial derivative \(\frac{\partial f}{\partial x}(a,b)\) as the slope at the point \((a,b,f(a,b))\) of the curve obtained as the intersection of the surface \(z=f(x,y)\) and the plane \(y=b\). The other partial derivative has a geometric interpretation. However, the surface \(z=f(x,y)\) contains infinitely many curves passing through \((a,b,f(a,b))\) whose slope we might choose to measure. The directional derivative enables us to do this.
Intuitively, \(\frac{\partial f}{\partial x}(a,b)\) is as the rate of change of \(f\) as we move infinitesimally from \(\mathbf{a}=(a,b)\) in the \(\mathbf{i}\) direction.
Mathematically, by the definition of the derivative of \(f\):
\[\begin{align*} \frac{\partial f}{\partial x}(a,b) &= \lim_{h \to 0} \frac{f(a+h,b) - f(a,b)}{h}\\ &=\lim_{h \to 0} \frac{f((a,b) + (h,0)) - f(a,b)}{h}\\ &=\lim_{h \to 0} \frac{f((a,b) + h(1,0)) - f(a,b)}{h}\\ &=\lim_{h \to 0} \frac{f(\mathbf{a} + h\mathbf{i}) - f(\mathbf{a})}{h} \end{align*}\]
Similarly, we have:
\[\begin{align*} \frac{\partial f}{\partial y}(a,b) = \lim_{h\to 0} \frac{f(\mathbf{a} + h\mathbf{j})-f(\mathbf{a})}{h} \end{align*}\]
Writing partial derivatives as we have enables us to see that they are special cases of a more general type of derivative. Suppose \(\mathbf{v}\) is a unit vector in \(\mathbf{R}^2\). The quantity:
\[\begin{align*} \lim_{h \to 0} \frac{f(\mathbf{a} + h\mathbf{v}) - f(\mathbf{a})}{h} \end{align*}\]
is nothing more than the rate of change of \(f\) as we move infinitesimally from \(\mathbf{a} = (a,b)\) in the direction specified by \(\mathbf{v}=(A,B) = A\mathbf{i} + B\mathbf{j}\).
Definition. Let \(\mathbf{v}\in \mathbf{R}^n\) be any unit vector, then the directional derivative of \(f\) at \(\mathbf{a}\) in the direction of \(\mathbf{v}\), denoted \(D_{\mathbf{v}}f(\mathbf{a})\) is:
\[\begin{align*} D_{\mathbf{v}}f(\mathbf{a}) = \lim_{h \to 0} \frac{f(\mathbf{a} + h\mathbf{v}) - f(\mathbf{a})}{h} \end{align*}\]
Let’s define a new function \(F\) of a single variable \(t\), by holding everything else constant:
\[\begin{align*} F(t) = f(\mathbf{a} + t\mathbf{v}) \end{align*}\]
Then, by the definition of directional derivatives, we have:
\[\begin{align*} D_{\mathbf{v}}f(\mathbf{a}) &= \lim_{t\to 0} \frac{f(\mathbf{a} + t\mathbf{v}) - f(\mathbf{a})}{t}\\ &= \lim_{t\to 0} \frac{F(t) - F(0)}{t - 0} \\ &= F'(0) \end{align*}\]
That is:
\[\begin{align*} D_{\mathbf{v}}f(\mathbf{a}) = \frac{d}{dt} f(\mathbf{a} + t\mathbf{v})\vert_{t=0} \end{align*}\]
Let \(\mathbf{x}(t) = \mathbf{a}+t\mathbf{v}\). Then, by the chain rule:
\[\begin{align*} \frac{d}{dt} f(\mathbf{a} + t\mathbf{v}) &= Df(\mathbf{x}) D\mathbf{x}(t) \\ &= \nabla f(\mathbf{x}) \cdot \mathbf{v} \end{align*}\]
This equation emphasizes the geometry of the situation. The directional derivative is just the dot product of the gradient vector and the direction vector \(\mathbf{v}\).
Theorem. Let \(f:X\to\mathbf{R}\) be differentiable at \(\mathbf{a}\in X\). Then, the directional derivative \(D_{\mathbf{v}}f(\mathbf{a})\) exists for all directions \(\mathbf{v}\in\mathbf{R}^n\) and moreover we have:
\[\begin{align*} D_{\mathbf{v}}f(\mathbf{a}) = \nabla f(\mathbf{x})\cdot \mathbf{v} \end{align*}\]
Gradients and steepest ascent
Suppose you are traveling in space near the planet Nilrebo and that one of your spaceship’s instruments measures the external atmospheric pressure on your ship as a function \(f(x,y,z)\) of position. Assume quite reasonably that this function is differentiable. Then, the directional derivative exists and if you travel from point \(\mathbf{a}=(a,b,c)\) in the direction of the unit vector \(\mathbf{u}=u\mathbf{i}+v\mathbf{j}+w\mathbf{k}\), the rate of change of pressure is given by:
\[\begin{align*} D_{\mathbf{u}}f(\mathbf{a}) = \nabla f(\mathbf{a}) \cdot \mathbf{u} = ||\nabla f(\mathbf{a})|| \cdot ||\mathbf{u}|| \cos \theta \end{align*}\]
where \(\theta\) is the angle between \(\mathbf{u}\) and the gradient vector \(\nabla f(\mathbf{a})\). Because, \(-1 \leq \cos \theta \leq 1\), and \(||\mathbf{u}||=1\), we have:
\[\begin{align*} - ||\nabla f(\mathbf{a})|| \leq D_{\mathbf{u}}f(\mathbf{a}) \leq ||\nabla f(\mathbf{a})|| \end{align*}\]
Moreover, \(\cos \theta = 1\) when \(\theta = 0\) and \(\cos \theta = -1\) when \(\theta = \pi\).
Theorem. The directional derivative \(D_{\mathbf{u}}f(\mathbf{a})\) is maximized, with respect to the direction, when \(\mathbf{u}\) points in the direction of the gradient vector \(f(\mathbf{a})\) and is minimized when \(\mathbf{u}\) points in the opposite direction. Furthermore, the maximum and minimum values of \(D_{\mathbf{u}}f(\mathbf{a})\) are \(||\nabla f(\mathbf{a})||\) and \(-||\nabla f(\mathbf{a})||\).
Theorem Let \(f:X \subseteq \mathbf{R}^n \to \mathbf{R}\) be a function of class \(C^1\). If \(\mathbf{x}_0\) is a point on the level set \(S=\{\mathbf{x} \in X | f(\mathbf{x}) = c\}\), then the gradient vector \(\nabla f(\mathbf{x}_0) \in \mathbf{R}^n\) is perpendicular to \(S\).
Proof. We need to establish the following: if \(\mathbf{v}\) is any vector tangent to \(S\) at \(\mathbf{x}_0\), then \(\nabla f(\mathbf{x}_0)\) is perpendicular to \(\mathbf{v}\) (i.e. \(\nabla f(\mathbf{x}_0) \cdot \mathbf{v} = 0\)). By a tangent vector to \(S\) at \(\mathbf{x}_0\), we mean that \(\mathbf{v}\) is the velocity vector of a curve \(C\) that lies in \(S\) and passes through \(\mathbf{x}_0\).
Let \(C\) be given parametrically by \(\mathbf{x}(t)=(x_1(t),\ldots,x_n(t))\) where \(a < t < b\) and \(\mathbf{x}(t_0) = \mathbf{x}_0\) for some number \(t_0\) in \((a,b)\).
\[\begin{align*} \frac{d}{dt}[f(\mathbf{x}(t))] &= Df(\mathbf{x}) \cdot \mathbf{x}'(t)\\ &= \nabla f(\mathbf{x}) \cdot \mathbf{v} \end{align*}\]
Evaluation at \(t = t_0\), yields:
\[\begin{align*} \nabla f (\mathbf{x}(t_0)) \cdot \mathbf{x}'(t_0) = \nabla f(\mathbf{x}_0) \cdot \mathbf{v} \end{align*}\]
On the other hand, since \(C\) is contained in \(S\), \(f(\mathbf{x})=c\). So,
\[\begin{align*} \frac{d}{dt}[f(\mathbf{x}(t))] &= \frac{d}{dt}[c] = 0 \end{align*}\]
Putting the above two facts together, we have the desired result.
Gradient Descent - Naive Implementation
Beginning at \(\mathbf{x}_0\), optimization algorithms generate a sequence of iterates \(\{\mathbf{x}_k\}_{k=0}^{\infty}\) that terminate when no more progress can be made or it seems a solution point has been approximated with sufficient accuracy. The gradient descent method is an optimization algorithm that moves along \(\mathbf{d}_k = -\nabla f(\mathbf{x}_k)\) at every step. Thus,
\[\begin{align*} \mathbf{x}_{k+1} = \mathbf{x}_k - \alpha_k \mathbf{d}_k \end{align*}\]
It can choose the step length \(\alpha_k\) in a variety of ways. One advantage of steepest descent is that it requires the calculation of the gradient \(\nabla f(\mathbf{x}_k)\), but not of the second derivatives. However, it can be excruciatingly slow on difficult problems.
from typing import Callable
import numpy as np
def gradient_descent(
func: Callable[[float], float],
alpha: float,
xval_0: np.array,
epsilon: float = 1e-5,
n_iter: int = 10000,
debug_step: int = 100,
):
"""
The gradient descent algorithm.
"""
xval_hist = []
funcval_hist = []
xval_curr = xval_0
error = 1.0
i = 0
while np.linalg.norm(error) > epsilon and i < n_iter:
# Save down x_curr and func(x_curr)
xval_hist.append(xval_curr)
funcval_hist.append(func(xval_curr))
# Calculate the forward difference
bump = 0.001
num_dims = len(xval_curr)
xval_bump = xval_curr + np.eye(num_dims) * bump
xval_nobump = np.full((num_dims, num_dims), xval_curr)
grad = np.array(
[
(func(xval_h) - func(xval)) / bump
for xval_h, xval in zip(xval_bump, xval_nobump)
]
)
# Compute the next iterate
xval_next = xval_curr - alpha * grad
# Compute the error vector
error = xval_next - xval_curr
if i % debug_step == 0:
print(
f"x[{i}] = {xval_curr}, f({xval_curr}) = {func(xval_curr)}, f'({xval_curr}) = {grad}, error={error}"
)
xval_curr = xval_next
i += 1
return xval_hist, funcval_histOne infamous test function is the Rosenbrock function defined as:
\[\begin{align*} f(x,y) = (a-x)^2 + b(y-x^2)^2 \end{align*}\]
def rosenbrock(x):
return 1*(1-x[0])**2 + 100*(x[1]-x[0]**2)**2
def f(x):
return x[0]**2 + x[1]**2Here is the plot of the Rosenbrock function with parameters \(a=1,b=100\).
Show the code
%%itikz --temp-dir --tex-packages=tikz,pgfplots --tikz-libraries=arrows --implicit-standalone
\begin{tikzpicture}[scale=1.5]
\begin{axis}[
title={Plot of $f(x,y)=(1-x)^2 + 100(y-x^2)^2$},
]
\addplot3 [surf] {(1-x)^2 + 100*(y-x^2)^2};
\end{axis}
\end{tikzpicture}
x_history, f_x_history = gradient_descent(
func=rosenbrock,
alpha=0.001,
xval_0=np.array([-2.0, 2.0]),
epsilon=1e-7,
debug_step=1000,
)
print(f"x* = {x_history[-1]}, f(x*)={f_x_history[-1]}")x[0] = [-2. 2.], f([-2. 2.]) = 409.0, f'([-2. 2.]) = [-1603.9997999 -399.9 ], error=[1.6039998 0.3999 ]
x[1000] = [-0.34194164 0.12278388], f([-0.34194164 0.12278388]) = 1.804241076974863, f'([-0.34194164 0.12278388]) = [-1.8359394 1.27195859], error=[ 0.00183594 -0.00127196]
x[2000] = [0.59082668 0.34719456], f([0.59082668 0.34719456]) = 0.16777685109400048, f'([0.59082668 0.34719456]) = [-0.23242066 -0.27632251], error=[0.00023242 0.00027632]
x[3000] = [0.71914598 0.51617916], f([0.71914598 0.51617916]) = 0.0789773438798074, f'([0.71914598 0.51617916]) = [-0.06806067 -0.09835534], error=[6.80606659e-05 9.83553399e-05]
x[4000] = [0.7626568 0.58094326], f([0.7626568 0.58094326]) = 0.05638109494458334, f'([0.7626568 0.58094326]) = [-0.02638936 -0.04042575], error=[2.63893643e-05 4.04257465e-05]
x[5000] = [0.78028032 0.60825002], f([0.78028032 0.60825002]) = 0.04831123625687607, f'([0.78028032 0.60825002]) = [-0.01115051 -0.01747329], error=[1.11505139e-05 1.74732947e-05]
x[6000] = [0.78785296 0.62017375], f([0.78785296 0.62017375]) = 0.045035368749296534, f'([0.78785296 0.62017375]) = [-0.00487137 -0.00770719], error=[4.87136843e-06 7.70718502e-06]
x[7000] = [0.79118466 0.62545602], f([0.79118466 0.62545602]) = 0.04363059164103049, f'([0.79118466 0.62545602]) = [-0.00215834 -0.00342913], error=[2.1583377e-06 3.4291304e-06]
x[8000] = [0.79266536 0.62781071], f([0.79266536 0.62781071]) = 0.04301342477692797, f'([0.79266536 0.62781071]) = [-0.00096218 -0.00153153], error=[9.62177510e-07 1.53153219e-06]
x[9000] = [0.79332635 0.62886327], f([0.79332635 0.62886327]) = 0.042739342077472306, f'([0.79332635 0.62886327]) = [-0.0004301 -0.00068518], error=[4.30102710e-07 6.85176669e-07]
x* = [0.7936218 0.62933403], f(x*)=0.04261711392593988Convergence.
When applying gradient descent in practice, we need to choose a value for the learning rate parameter \(\alpha\). An error surface \(E\) is usually a convex function on the weight space \(\mathbf{w}\). Intuitively, we might expect that increasing the value of \(\alpha\) should lead to bigger steps through the weight space and hence faster convergence. However, the successive steps oscillate back and forth across the valley, and if we increase \(\alpha\) too much, these oscillations will become divergent. Because \(\alpha\) must be kept sufficiently small to avoid divergent oscillations across the valley, progress along the valley is very slow. Gradient descent then takes many small steps to reach the minimum and is a very inefficient procedure.
We can gain deeper insight into this problem, by considering a quadratic approximation to the error function in the neighbourhood of the minimum. Let the error function be given by:
\[\begin{align*} f(w) = \frac{1}{2}w^T A w - b^T w, \quad w\in\mathbf{R}^n \end{align*}\]
where \(A\) is symmetric and \(A \succ 0\).
Differentiating on both sides, the gradient of the error function is:
\[\begin{align*} \nabla f(w) = Aw - b \end{align*}\]
and the hessian is:
\[\begin{align*} \nabla^2 f(w) = A \end{align*}\]
The critical points of \(f\) are given by:
\[\begin{align*} \nabla f(w^*) &= 0\\ Aw^{*} - b &= 0\\ w^{*} &= A^{-1}b \end{align*}\]
and
\[\begin{align*} f(w^{*}) &= \frac{1}{2}(A^{-1}b)^T A (A^{-1}b) - b^T (A^{-1} b)\\ &= \frac{1}{2}b^T A^{-1} A A^{-1} b -b^T A^{-1} b \\ &= \frac{1}{2}b^T A^{-1} b - b^T A^{-1} b \\ &= -\frac{1}{2}b^T A^{-1} b \end{align*}\]
Therefore, the iterates of \(w\) are:
\[\begin{align*} w^{(k+1)} = w^{(k)} - \alpha(Aw^{(k)} - b) \end{align*}\]
By the spectral theorem, every symmetric matrix \(A\) is orthogonally diagonalizable. So, \(A\) admits a factorization:
\[\begin{align*} A = Q \Lambda Q^T \end{align*}\]
where \(\Lambda = diag(\lambda_1,\ldots,\lambda_n)\) and as per convention, we will assume that \(\lambda_i\)are sorted from smallest \(\lambda_1\) to biggest \(\lambda_n\).
Recall that \(Q=[q_1,\ldots,q_n]\), where \(q_i\) are the eigenvectors of \(A\) and \(Q\) is the change of basis matrix from the standard basis to the eigenvector basis. So, if \(a \in \mathbf{R}^n\) are the coordinates of a vector in the standard basis and \(b \in \mathbf{R}^n\) are its coordinates in the eigenvector basis, then \(a = Qb\) or \(b=Q^T a\).
Let \(x^{(k)}=Q^T(w^{(k)}-w^{*})\). Equivalently, \(w^{(k)} = Qx^{(k)} + w^{*}\). Thus, we are shifting the origin to \(w^{*}\) and changing the axes to be aligned with the eigenvectors. In this new coordinate system,
\[\begin{align*} Qx^{(k+1)} + w^{*} &= Qx^{(k)} + w^{*} - \alpha(AQx^{(k)} + Aw^{*} - b)\\ Qx^{(k+1)} &= Qx^{(k)} - \alpha(AQx^{(k)} + Aw^{*} - b)\\ Qx^{(k+1)} &= Qx^{(k)} - \alpha(AQx^{(k)} + A(A^{-1}b) - b)\\ & \quad \{\text{Substituting } w^{*}=A^{-1}b \}\\ Qx^{(k+1)} &= Qx^{(k)} - \alpha(AQx^{(k)})\\ Qx^{(k+1)} &= Qx^{(k)} - \alpha(Q\Lambda Q^T Qx^{(k)})\\ & \quad \{\text{Substituting } A = Q\Lambda Q^T \}\\ Qx^{(k+1)} &= Qx^{(k)} - \alpha(Q\Lambda x^{(k)})\\ & \quad \{\text{Using } Q^T Q = I \}\\ x^{(k+1)} &= x^{(k)} - \alpha\Lambda x^{(k)} \end{align*}\]
The \(i\)-th coordinate of this recursive system is given by:
\[\begin{align*} x_i^{(k+1)} &= x_i^{(k)} - \alpha\lambda_i x_i^{(k)}\\ &= (1-\alpha \lambda_i)x_i^{(k)}\\ &= (1-\alpha \lambda_i)^{k+1}x_i^{(0)} \end{align*}\]
Moving back to our original space \(w\), we can see that:
\[\begin{align*} w^{(k)} - w^{*} = Qx^{(k)} &= \sum_i q_i x_i^{(k)}\\ &= \sum_i q_i (1-\alpha \lambda_i)^{k+1} x_i^{(0)} \end{align*}\]
and there we have it - gradient descent in the closed form.
Decomposing the error
The above equation admits a simple interpretation. Each element of \(x^{(0)}\) is the component of the error in the initial guess in \(Q\)-basis. There are \(n\) such errors and each of these errors follow their own, solitary path to the minimum, decreasing exponentially with a compounding rate of \(1-\alpha \lambda_i\). The closer that number is to \(1\), the slower it converges.
For most step-sizes, the eigenvectors with the largest eigenvalues converge the fastest. This triggers an explosion of progress in the first few iterations, before things slow down, as the eigenvectors with smaller eigenvalues’ struggles are revealed. It’s easy to visualize this - look at the sequences of \(\frac{1}{2^k}\) and \(\frac{1}{3^k}\).
Show the code
%%itikz --temp-dir --tex-packages=tikz,pgfplots --tikz-libraries=arrows --implicit-standalone
\begin{tikzpicture}[scale=1.5]
\begin{axis}[
title={Comparison of the rates of convergence},
xlabel={$n$},
ylabel={$f(n)$}
]
\addplot [domain=0:5,samples=400,blue] {1/(2^x)} node [midway,above] {$2^{-n}$};
\addplot [domain=0:5,samples=400,red] {1/(3^x)} node [midway,below] {$3^{-n}$};
\end{axis}
\end{tikzpicture}
Choosing a step size
The above analysis gives us immediate guidance as to how to set a step-size \(\alpha\). In order to converge, each \(|1-\alpha \lambda_i| < 1\). All workable step-sizes, therefore, fall in the interval:
\[\begin{align*} -1 &\leq 1 - \alpha \lambda_i &\leq 1 \\ -2 &\leq - \alpha \lambda_i &\leq 0 \\ 0 &\leq \alpha \lambda_i &\leq 2 \end{align*}\]
Because \((1-\alpha \lambda_i)\) could be either positive or negative, the overall convergence rate is determined by the slowest error component, which must be either \(\lambda_1\) or \(\lambda_n\):
\[\begin{align*} \text{rate}(\alpha) = \max \{|1-\alpha \lambda_1|,|1-\alpha \lambda_n|\} \end{align*}\]
The optimal learning rate is that which balances the convergence rate. Setting the convergence rate to be equal for the smallest and largest eigenvalues, we can solve for the optimal step size.
\[\begin{align*} |1- \alpha \lambda_1| = |1- \alpha \lambda_n| \end{align*}\]
Assuming \(\lambda_1 \neq \lambda_n\):
\[\begin{align*} 1 - \alpha \lambda_1 &= -1 + \alpha \lambda_n\\ \alpha (\lambda_1 + \lambda_n) &= 2\\ \alpha^* &= \frac{2}{\lambda_1 + \lambda_n} \end{align*}\]
So, the optimal convergence rate equals:
\[\begin{align*} \max \{|1-\alpha \lambda_1|,|1-\alpha \lambda_n|\} &= 1 - \frac{2\lambda_1}{\lambda_1 + \lambda_n} \\ &= \frac{\lambda_n - \lambda_1}{\lambda_n + \lambda_1}\\ &= \frac{\kappa - 1}{\kappa + 1} \end{align*}\]
The ratio \(\kappa = \lambda_n / \lambda_1\) determines the convergence rate of the problem. Recall that the level curves of the error surface are ellipsoids. Hence, a poorly conditioned Hessian results in stretching one of the axes of the ellipses, and taken to its extreme, the contours are almost parallel. Since gradient vectors are orthogonal to the level curves, the optimizer keeps pin-balling between parallel lines and takes forever to reach the center.
Stochastic Gradient Descent(SGD)
In machine learning applications, we typically want to minimize the loss function \(\mathcal{L}(w)\) that has the form of a sum:
\[\begin{align*} \mathcal{L}(w) = \frac{1}{n}\sum_i L_i(w) \end{align*}\]
where the weights \(w\) (and the biases) are to be estimated. Each summand function \(L_i\) is typically associated with the \(i\)-th sample in the data-set used for training.
When we minimize the above function with respect to the weights and biases, a standard gradient descent method would perform the following operations:
\[\begin{align*} w_{k+1} := w_k - \alpha_k \nabla \mathcal{L}(w_{k}) = w_k - \frac{\alpha_k}{n}\sum_{i} \nabla L_i(w_{k}) \end{align*}\]
In the stochastic (or online) gradient descent algorithm, the true gradient of \(\mathcal{L}(w)\) is approximated by the gradient at a single sample:
\[\begin{align*} w_{k+1} := w_k - \alpha_k \nabla \mathcal{L}(w_{k}) = w_k - \alpha_k \nabla L_i(w_{k}) \end{align*}\]
SGDOptimizer class
We are now in a position to code the SGDOptimizer class.
# Global imports
import numpy as np
import nnfs
import matplotlib.pyplot as plt
from nnfs.datasets import spiral_data
from dense_layer import DenseLayer
from relu_activation import ReLUActivation
from softmax_activation import SoftmaxActivation
from loss import Loss
from categorical_cross_entropy_loss import CategoricalCrossEntropyLoss
from categorical_cross_entropy_softmax import CategoricalCrossEntropySoftmaxclass SGDOptimizer:
# Initialize the optimizer
def __init__(self, learning_rate=1.0):
self.learning_rate = learning_rate
# Update the parameters
def update_params(self, layer):
layer.weights -= self.learning_rate * layer.dloss_dweights
layer.biases -= self.learning_rate * layer.dloss_dbiasesLet’s play around with our optimizer.
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create a DenseLayer with 2 input features and 64 neurons
dense1 = DenseLayer(2, 64)
# Create ReLU Activation (to be used with DenseLayer 1)
activation1 = ReLUActivation()
# Create the second DenseLayer with 64 inputs and 3 output values
dense2 = DenseLayer(64,3)
# Create SoftmaxClassifer's combined loss and activation
loss_activation = CategoricalCrossEntropySoftmax()
# The next step is to create the optimizer object
optimizer = SGDOptimizer()Now, we perform a forward pass of our sample data.
# Perform a forward pass for our sample data
dense1.forward(X)
# Performs a forward pass through the activation function
# takes the output of the first dense layer here
activation1.forward(dense1.output)
# Performs a forward pass through the second DenseLayer
dense2.forward(activation1.output)
# Performs a forward pass through the activation/loss function
# takes the output of the second DenseLayer and returns the loss
loss = loss_activation.forward(dense2.output, y)
# Let's print the loss value
print(f"Loss = {loss}")
# Now we do our backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dloss_dz)
activation1.backward(dense2.dloss_dinputs)
dense1.backward(activation1.dloss_dz)
# Then finally we use our optimizer to update the weights and biases
optimizer.update_params(dense1)
optimizer.update_params(dense2)Loss = 1.0986526582562541This is everything we need to train our model!
But why would we only perform this optimization only once, when we can perform it many times by leveraging Python’s looping capabilities? We will repeatedly perform a forward pass, backward pass and optimization until we reach some stopping point. Each full pass through all of the training data is called an epoch.
In most deep learning tasks, a neural network will be trained for multiple epochs, though the ideal scenario would be to have a perfect model with ideal weights and biases after only one epoch. To add multiple epochs of our training into our code, we will initialize our model and run a loop around all the code performing the forward pass, backward pass and optimization calculations.
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create a dense layer with 2 input features and 64 output values
dense1 = DenseLayer(2, 64)
# Create ReLU Activation (to be used with the DenseLayer)
activation1 = ReLUActivation()
# Create a second DenseLayer with 64 input features (as we take
# output of the previous layer here) and 3 output values (output values)
dense2 = DenseLayer(64, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = CategoricalCrossEntropySoftmax()
# Create optimizer
optimizer = SGDOptimizer()
# Train in loop
for epoch in range(10001):
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through the activation function
# takes the output of the first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second DenseLayer
# takes the outputs of the activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of the second DenseLayer here and returns the loss
loss = loss_activation.forward(dense2.output, y)
if not epoch % 1000:
print(f"Epoch: {epoch}, Loss: {loss: .3f}")
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dloss_dz)
activation1.backward(dense2.dloss_dinputs)
dense1.backward(activation1.dloss_dz)
# Update the weights and the biases
optimizer.update_params(dense1)
optimizer.update_params(dense2)Epoch: 0, Loss: 1.099
Epoch: 1000, Loss: 1.029
Epoch: 2000, Loss: 0.962
Epoch: 3000, Loss: 0.848
Epoch: 4000, Loss: 0.699
Epoch: 5000, Loss: 0.544
Epoch: 6000, Loss: 0.508
Epoch: 7000, Loss: 0.478
Epoch: 8000, Loss: 0.460
Epoch: 9000, Loss: 0.443
Epoch: 10000, Loss: 0.419Our neural network mostly stays stuck at around a loss of \(1.0\) and later around \(0.85\)-\(0.90\) Given that this loss didn’t decrease much, we can assume that this learning rate being too high, also caused the model to get stuck in a local minimum, which we’ll learn more about soon. Iterating over more epochs, doesn’t seem helpful at this point, which tells us that we’re likely stuck with our optimization. Does this mean that this is the most we can get from our optimizer on this dataset?
Recall that we’re adjusting our weights and biases by applying some fraction, in this case \(1.0\) to the gradient and subtracting this from the weights and biases. This fraction is called the learning rate (LR) and is the primary adjustable parameter for the optimizer as it decreases loss.
Learning Rate Decay
The idea of a learning rate decay is to start with a large learning rate, say \(1.0\) in our case and then decrease it during training. There are a few methods for doing this. One option is program a decay rate, which steadily decays the learning rate per batch or per epoch.
Let’s plan to decay per step. This can also be referred to as \(1/t\) decaying or exponential decaying. Basically, we’re going to update the learning rate each step by the reciprocal of the step count fraction. This fraction is a new hyper parameter that we’ll add to the optimizer, called the learning rate decay.
initial_learning_rate = 1.0
learning_rate_decay = 0.1
for step in range(10):
learning_rate = initial_learning_rate * 1.0 / (1 + learning_rate_decay * step)
print(learning_rate)1.0
0.9090909090909091
0.8333333333333334
0.7692307692307692
0.7142857142857143
0.6666666666666666
0.625
0.588235294117647
0.5555555555555556
0.5263157894736842The derivative of the function \(\frac{1}{1+x}\) is \(-\frac{1}{(1+x)^2}\).
Show the code
%%itikz --temp-dir --tex-packages=tikz,pgfplots --tikz-libraries=arrows --implicit-standalone
\begin{tikzpicture}[scale=1.5]
\begin{axis}[
title={Plot of $f(x)=-\frac{1}{(1+x)^2}$},
xlabel={$x$},
ylabel={$f(x)$}
]
\addplot [domain=0:1,samples=400] {-1/(( 1 + x)^2)};
\end{axis}
\end{tikzpicture}
The learning rate drops fast initially, but the change in the learning rate lowers in each step. We can update our SGDOptimizer class to allow for the learning rate decay.
class SGDOptimizer:
# Initial optimizer - set settings
# learning rate of 1. is default for this optimizer
def __init__(self, learning_rate=1.0, decay=0.0):
self.learning_rate = learning_rate
self.current_learning_rate = learning_rate
self.decay = decay
self.iterations = 0
# Call once before any parameter updates
def pre_update_params(self):
if self.decay:
self.current_learning_rate = self.learning_rate * (
1.0 / (1.0 + self.decay * self.iterations)
)
# Update parameters
def update_params(self, layer):
layer.weights += -self.current_learning_rate * layer.dloss_dweights
layer.biases += -self.current_learning_rate * layer.dloss_dbiases
def post_update_params(self):
self.iterations += 1Let’s use a decay rate of \(0.01\) and train our neural network again.
def train(decay):
# Create a dataset
X, y = spiral_data(samples=100, classes=3)
# Create a dense layer with 2 input features and 64 output values
dense1 = DenseLayer(2, 64)
# Create ReLU activation (to be used with the dense layer)
activation1 = ReLUActivation()
# Create second DenseLayer with 64 input features (as we take output of the
# previous layer here) and 3 output values
dense2 = DenseLayer(64, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = CategoricalCrossEntropySoftmax()
# Create optimizer
optimizer = SGDOptimizer(learning_rate=1.0,decay=decay)
acc_vals = []
loss_vals = []
lr_vals = []
# Train in a loop
for epoch in range(10001):
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through the activation function
# takes the output of the first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second DenseLayer
# takes the outputs of the activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of the second DenseLayer here and returns the loss
loss = loss_activation.forward(dense2.output, y)
# Calculate accuracy from output of activation2 and targets
# Calculate values along the first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y.shape) == 2:
y = np.argmax(y, axis=1)
accuracy = np.mean(predictions == y)
if epoch % 1000 == 0:
print(
f"epoch: {epoch}, \
acc : {accuracy:.3f}, \
loss: {loss: .3f}, \
lr : {optimizer.current_learning_rate}"
)
acc_vals.append(accuracy)
loss_vals.append(loss)
lr_vals.append(optimizer.current_learning_rate)
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dloss_dz)
activation1.backward(dense2.dloss_dinputs)
dense1.backward(activation1.dloss_dz)
# Update the weights and the biases
optimizer.pre_update_params()
optimizer.update_params(dense1)
optimizer.update_params(dense2)
optimizer.post_update_params()
return acc_vals, loss_vals, lr_valsacc_vals, loss_vals, lr_vals = train(decay=0.01)epoch: 0, acc : 0.333, loss: 1.099, lr : 1.0
epoch: 1000, acc : 0.477, loss: 1.066, lr : 0.09099181073703366
epoch: 2000, acc : 0.457, loss: 1.065, lr : 0.047641734159123386
epoch: 3000, acc : 0.453, loss: 1.065, lr : 0.03226847370119393
epoch: 4000, acc : 0.450, loss: 1.064, lr : 0.02439619419370578
epoch: 5000, acc : 0.440, loss: 1.064, lr : 0.019611688566385566
epoch: 6000, acc : 0.443, loss: 1.063, lr : 0.016396130513198885
epoch: 7000, acc : 0.447, loss: 1.063, lr : 0.014086491055078181
epoch: 8000, acc : 0.447, loss: 1.063, lr : 0.012347203358439314
epoch: 9000, acc : 0.447, loss: 1.062, lr : 0.010990218705352238
epoch: 10000, acc : 0.447, loss: 1.062, lr : 0.009901970492127933Show the code
plt.grid(True)
epochs = np.linspace(0,10000,10001)
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.plot(epochs,acc_vals)
plt.show()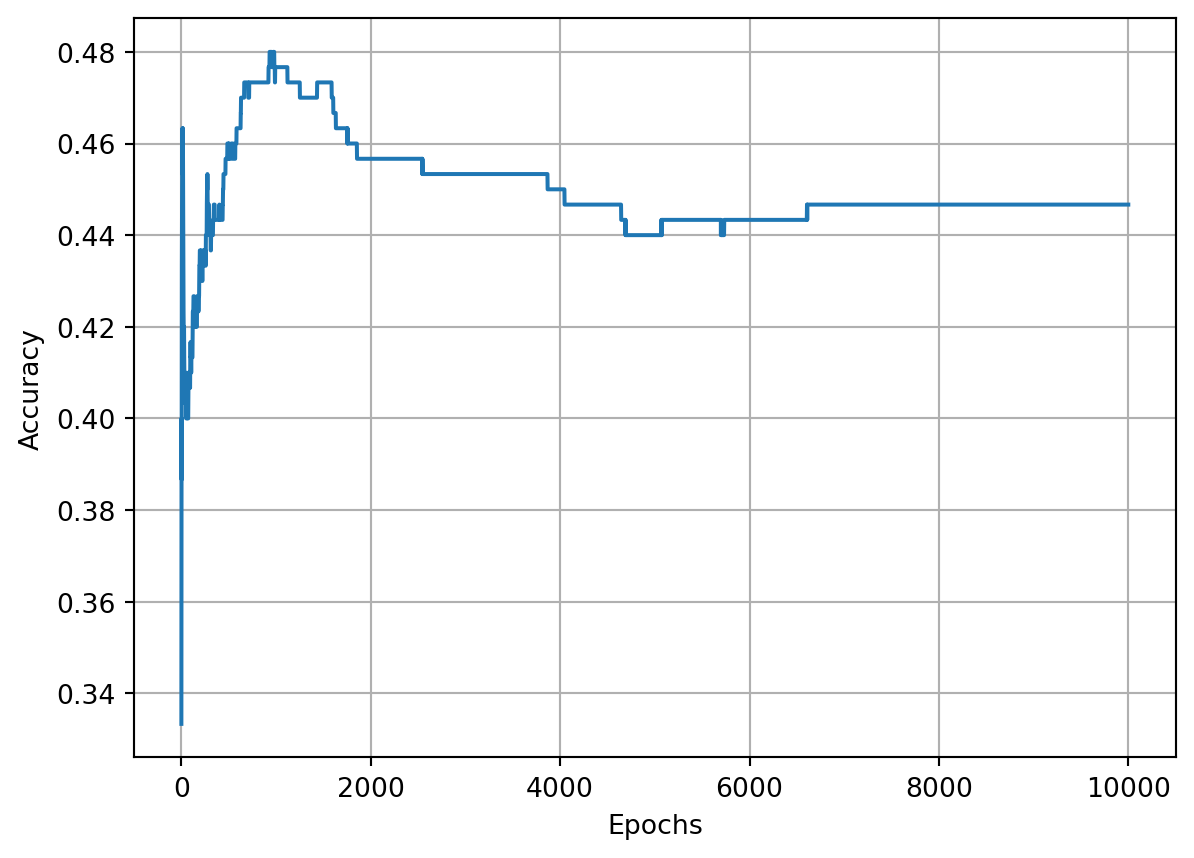
Show the code
plt.grid(True)
plt.ylabel('Loss')
plt.xlabel('Epochs')
plt.plot(epochs,loss_vals)
plt.show()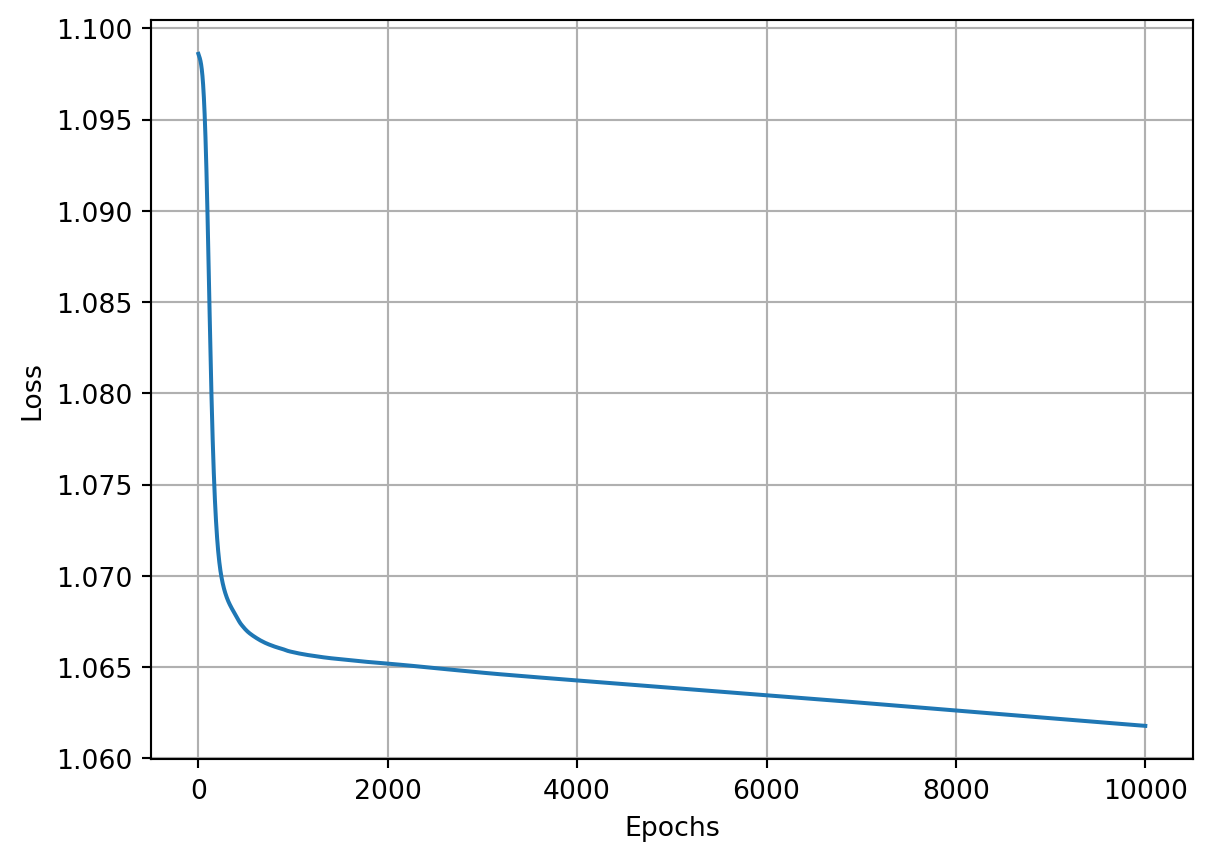
Show the code
plt.grid(True)
plt.ylabel("Learning rate")
plt.xlabel("Epochs")
plt.plot(epochs, lr_vals)
plt.show()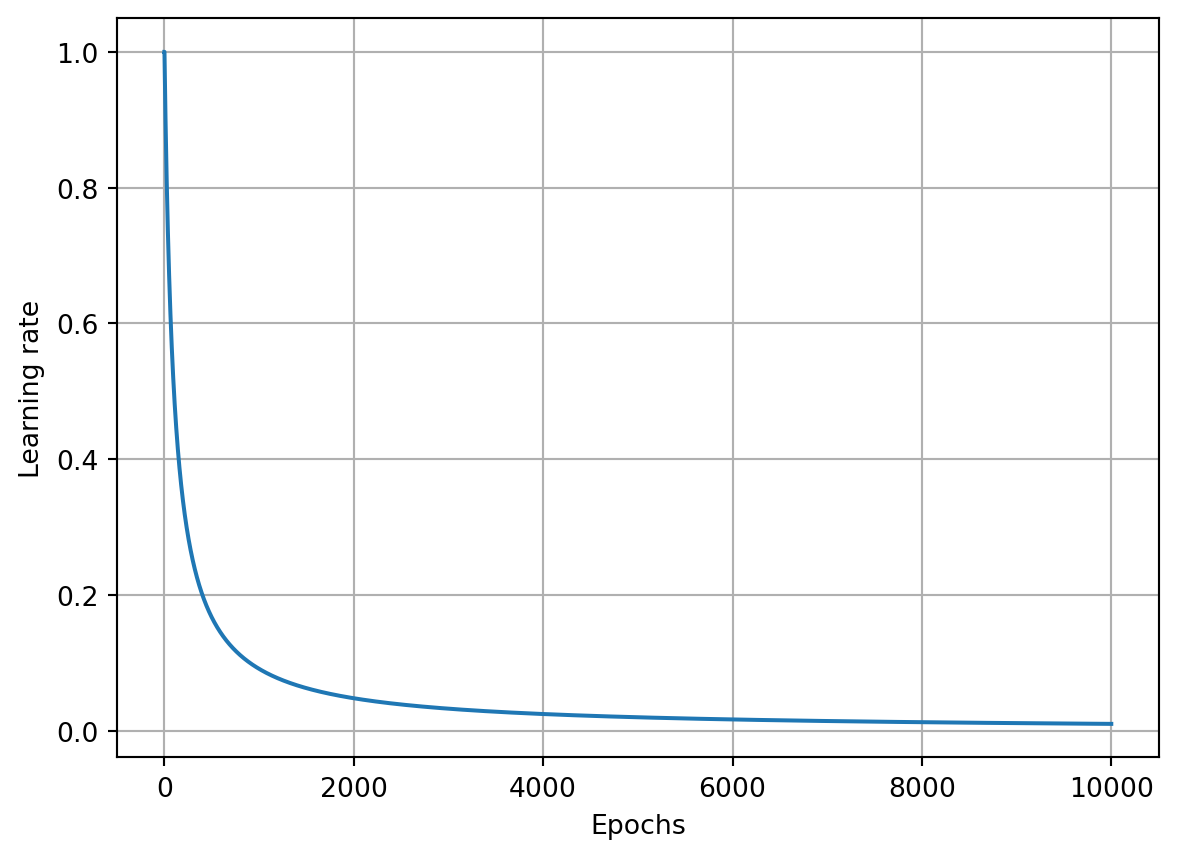
The optimization algorithm appears to be stuck and the reason is because the learning rate decayed far too quickly and became too small, trapping the optimizer in some local minimum. We can, instead, try to decay a bit slower by making our decay a smaller number. For example, let’s go with \(10^{-3}\).
acc_vals, loss_vals, lr_vals = train(decay=1e-3)epoch: 0, acc : 0.327, loss: 1.099, lr : 1.0
epoch: 1000, acc : 0.410, loss: 1.066, lr : 0.5002501250625312
epoch: 2000, acc : 0.413, loss: 1.055, lr : 0.33344448149383127
epoch: 3000, acc : 0.457, loss: 1.014, lr : 0.25006251562890724
epoch: 4000, acc : 0.527, loss: 0.968, lr : 0.2000400080016003
epoch: 5000, acc : 0.547, loss: 0.935, lr : 0.16669444907484582
epoch: 6000, acc : 0.563, loss: 0.918, lr : 0.1428775539362766
epoch: 7000, acc : 0.573, loss: 0.900, lr : 0.12501562695336915
epoch: 8000, acc : 0.577, loss: 0.882, lr : 0.11112345816201799
epoch: 9000, acc : 0.590, loss: 0.860, lr : 0.1000100010001
epoch: 10000, acc : 0.603, loss: 0.845, lr : 0.09091735612328393Show the code
plt.grid(True)
epochs = np.linspace(0,10000,10001)
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.plot(epochs,acc_vals)
plt.show()
Show the code
plt.grid(True)
plt.ylabel('Loss')
plt.xlabel('Epochs')
plt.plot(epochs,loss_vals)
plt.show()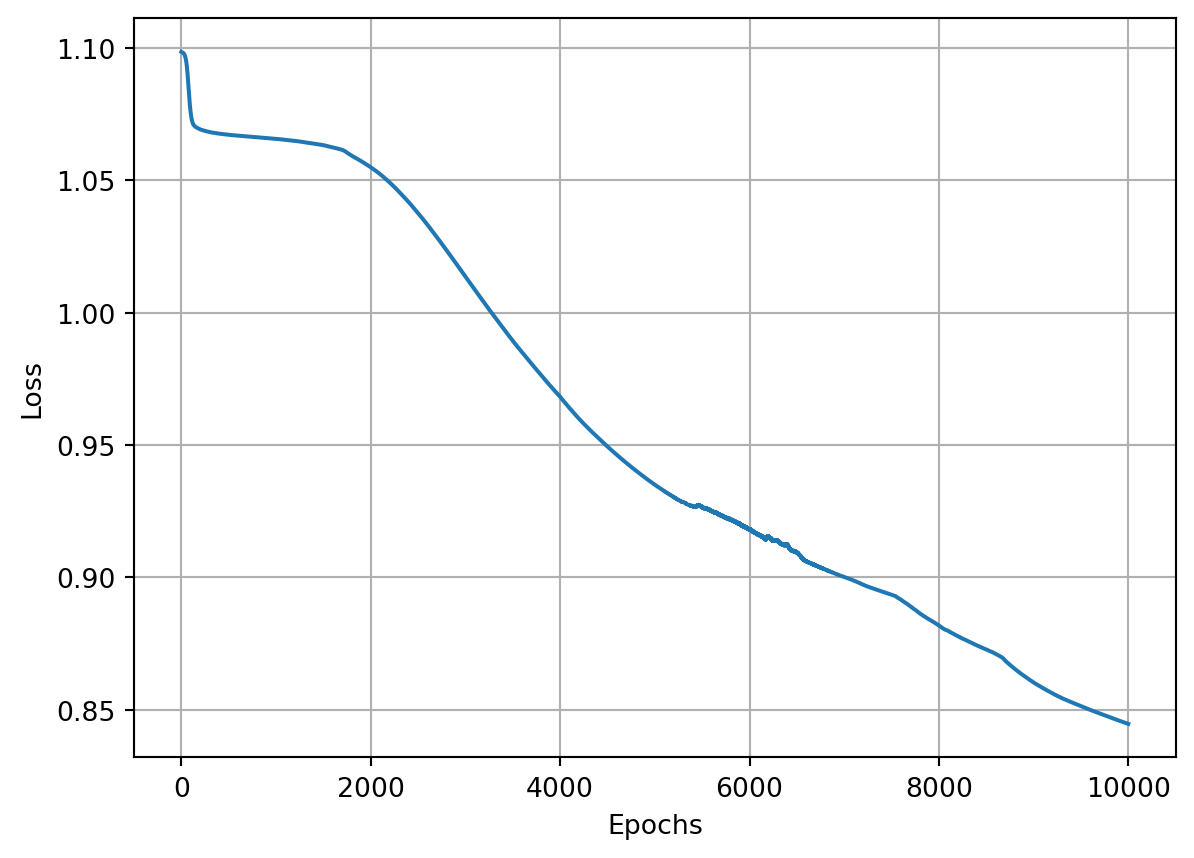
Show the code
plt.grid(True)
plt.ylabel("Learning rate")
plt.xlabel("Epochs")
plt.plot(epochs, lr_vals)
plt.show()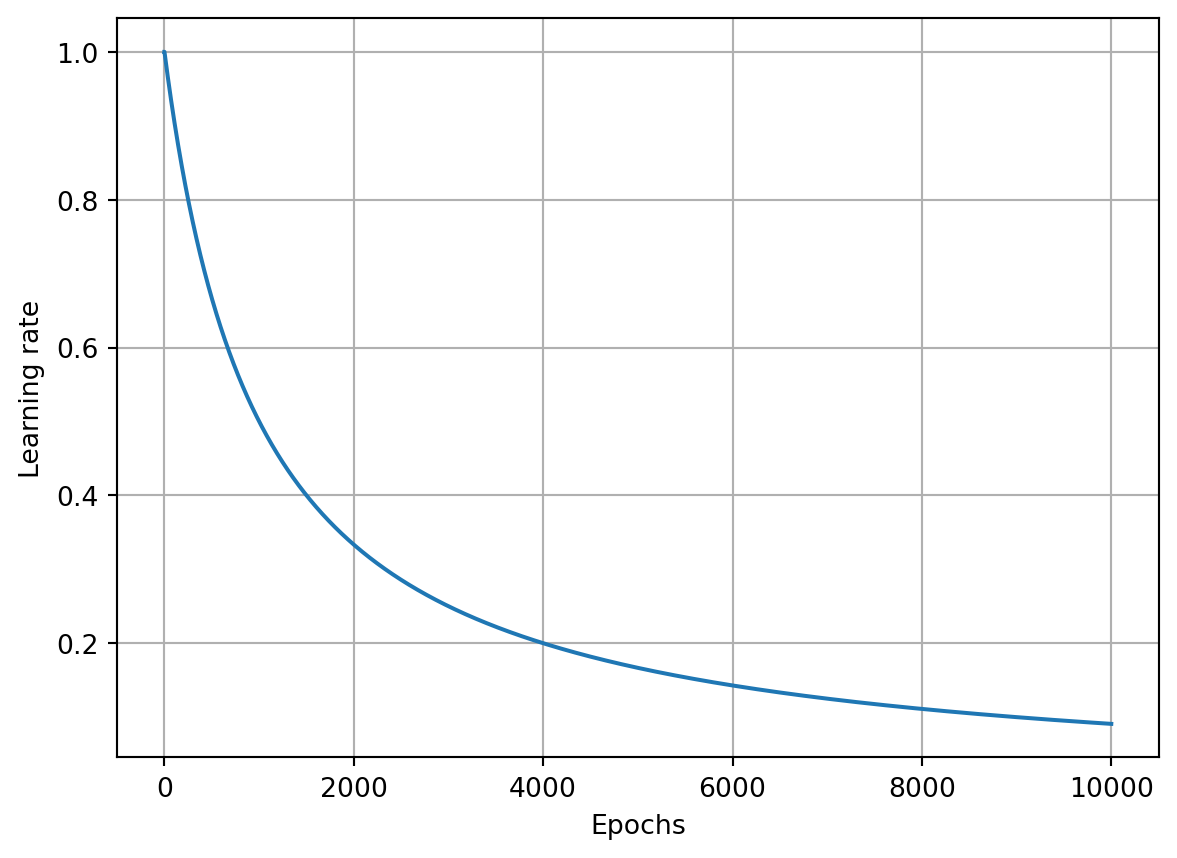
Stochastic Gradient Descent with Momentum
Momentum proposes a small tweak to gradient descent. We give gradient descent a short-term memory. Let’s define the updated velocity \(z^{k+1}\) to be weighted and controlled by the mass \(\beta\). When \(\beta\) is high, we simply use the velocity from the last time, that is, we are entirely driven by momentum. When \(\beta=0\), the momentum is zero.
\[\begin{align*} z^{(k+1)} &= \beta z^{(k)} + \nabla f(w^{(k)})\\ w^{k+1} &= w^k - \alpha z^{k+1} \end{align*}\]
\(z^{(k+1)}\) is called the velocity. It accumulates the past gradients similar to how a heavy ball rolling down the error function landscape integrates over past forces. To see what’s happening in more detail, we can recursively write out:
\[\begin{align*} z^{(k)} &= \beta z^{k-1} + \nabla f(w^{(k-1)}) \\ &= \beta(\beta z^{k-2} + \nabla f(w^{(k-2)})) + \nabla f(w^{(k-1)})\\ &= \beta^2 z^{k-2} + \beta \nabla f(w^{(k-2)}) + \nabla f(w^{(k-1)})\\ &= \beta^2 (\beta z^{k-3} + \nabla f(w^{(k-3)}) ) + \beta \nabla f(w^{(k-2)}) + \nabla f(w^{(k-1)})\\ &= \sum_{t=0}^{k} \beta^t \nabla f(w^{(k-1-t)}) \end{align*}\]
The new gradient replacement no longer points into the direction of steepest descent on a particular instance any longer but rather in the direction of an exponentially weighted average of past gradients.
The dynamics of Momentum
Since \(\nabla f(w^k) = Aw^k - b\), the update on the quadratic is:
\[\begin{align*} z^{k+1} &= \beta z^k + (Aw^k - b)\\ w^{k+1} &= w^k - \alpha z^{k+1} \end{align*}\]
We go through the same motions as before with the change of basis \((w^k - w^{*})=Qx^k\) and \(z^k = Q y^k\) to yield the update rule:
\[\begin{align*} Q y^{k+1} &= \beta Q y^k + (AQx^k + Aw^* - b)\\ Q y^{k+1} &= \beta Q y^k + (AQx^k + AA^{-1}b - b)\\ Q y^{k+1} &= \beta Q y^k + Q\Lambda Q^T Q x^k\\ Q y^{k+1} &= \beta Q y^k + Q\Lambda x^k\\ y^{k+1} &= \beta y^k + \Lambda x^k \end{align*}\]
or equivalently:
\[\begin{align*} y_i^{k+1} &= \beta y_i^k + \lambda_i x_i^k \end{align*}\]
Moreover,
\[\begin{align*} Qx^{k+1} + w^* &= Qx^k + w^* - \alpha Qy^{k+1}\\ x^{k+1} &= x^k - \alpha y^{k+1} \end{align*}\]
or equivalently:
\[\begin{align*} x_i^{k+1} &= x_i^k - \alpha y_i^{k+1} \end{align*}\]
This lets us rewrite our iterates as:
\[\begin{align*} \begin{bmatrix} y_i^{k+1}\\ x_i^{k+1} \end{bmatrix} &= \begin{bmatrix} \beta y_i^k + \lambda_i x_i^k\\ (1-\alpha\lambda_i)x_i^k - \alpha \beta y_i^k \end{bmatrix}\\ &=\begin{bmatrix} \beta & \lambda_i\\ - \alpha \beta & (1-\alpha\lambda_i) \end{bmatrix} \begin{bmatrix} y_i^k\\ x_i^k \end{bmatrix} \end{align*}\]
Consequently,
\[\begin{align*} \begin{bmatrix} y_i^k\\ x_i^k \end{bmatrix} = R^k \begin{bmatrix} y_i^0\\ x_i^0 \end{bmatrix},\quad R = \begin{bmatrix} \beta & \lambda_i\\ - \alpha \beta & (1-\alpha\lambda_i) \end{bmatrix} \end{align*}\]
In the case of \(2 \times 2\) matrix, there is an elegant little known formula in terms of the eigenvalues of the matrix \(R\), \(\sigma_1\) and \(\sigma_2\):
\[\begin{align*} R^k = \begin{cases} \sigma_1^k R_1 - \sigma_2^k R_2 & \sigma_1 \neq \sigma_2,\\ \sigma_1^k(kR\sigma_1-(k-1)I) & \sigma_1 = \sigma_2 \end{cases} \quad R_j = \frac{R-\sigma_j I}{\sigma_1 - \sigma_2} \end{align*}\]
The formula is rather complicated, but the takeway here is that it plays the exact same role the individual convergence rates \((1-\alpha \lambda_i)\) do in gradient descent. The convergence rate is therefore the slowest of the two rates, \(\max \{|\sigma_1|,|\sigma_2|\}\).
For what values of \(\alpha\) and \(\beta\) does momentum converge? Since we need both \(\sigma_1\) and \(\sigma_2\) to converge, our convergence criterion is now \(\max \{|\sigma_1|,|\sigma_2|\} < 1\).
It can be shown that when we choose an optimal value of the parameters \(\alpha\) and \(\beta\), the convergence rate is proportional to:
\[\begin{align*} \frac{\sqrt{\kappa} - 1}{\sqrt{\kappa} + 1} \end{align*}\]
With barely a modicum of extra effort, we have square-rooted the condition number.
Adding momentum to the SGDOptimizer class
We are now in a position to add momentum to the SGDOptimizer class.
class SGDOptimizer:
# Initial optimizer - set settings
# learning rate of 1. is default for this optimizer
def __init__(self, learning_rate=1.0, decay=0.0, momentum=0.0):
self.learning_rate = learning_rate
self.current_learning_rate = learning_rate
self.decay = decay
self.iterations = 0
self.beta = momentum
# Call once before any parameter updates
def pre_update_params(self):
if self.decay:
self.current_learning_rate = self.learning_rate * (
1.0 / (1.0 + self.decay * self.iterations)
)
# Update parameters
def update_params(self, layer):
# If we use momentum
if self.beta:
# If the layer does not contain momentum arrays, create them
# filled with zeros
if not hasattr(layer, "weight_momentums"):
layer.weight_momentums = np.zeros_like(layer.dloss_dweights)
# If there is no momentumm array for weights
# the array doesnt exist for biases yet either
layer.bias_momentums = np.zeros_like(layer.dloss_dbiases)
# Build weight updates with momentum - take previous
# updates multiplied by retain factor and update with
# with current gradients
# v[t+1] = \beta * v[t] + \alpha * dL/dw
weight_updates = (
self.beta * layer.weight_momentums
+ self.current_learning_rate * layer.dloss_dweights
)
layer.weight_momentums = weight_updates
# Build bias updates
bias_updates = (
self.beta * layer.bias_momentums
+ self.current_learning_rate * layer.dloss_dbiases
)
layer.bias_momentums = bias_updates
else:
# Vanilla SGD updates (as before momentum update)
weight_updates = self.current_learning_rate * layer.dloss_dweights
bias_updates = self.current_learning_rate * layer.dloss_dbiases
layer.weights -= weight_updates
layer.biases -= bias_updates
def post_update_params(self):
self.iterations += 1Let’s see an example illustrating how adding momentum changes the learning process. Keeping the same learning_rate=1.0 and decay=1e-3 from the previous training attempt and using a momentum of 0.50:
def train(decay, momentum):
# Create a dataset
X, y = spiral_data(samples=100, classes=3)
# Create a dense layer with 2 input features and 64 output values
dense1 = DenseLayer(2, 64)
# Create ReLU activation (to be used with the dense layer)
activation1 = ReLUActivation()
# Create second DenseLayer with 64 input features (as we take output of the
# previous layer here) and 3 output values
dense2 = DenseLayer(64, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = CategoricalCrossEntropySoftmax()
# Create optimizer
optimizer = SGDOptimizer(learning_rate=1.0,decay=decay,momentum=momentum)
acc_vals = []
loss_vals = []
lr_vals = []
# Train in a loop
for epoch in range(10001):
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through the activation function
# takes the output of the first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second DenseLayer
# takes the outputs of the activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of the second DenseLayer here and returns the loss
loss = loss_activation.forward(dense2.output, y)
# Calculate accuracy from output of activation2 and targets
# Calculate values along the first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y.shape) == 2:
y = np.argmax(y, axis=1)
accuracy = np.mean(predictions == y)
if epoch % 1000 == 0:
print(
f"epoch: {epoch}, \
acc : {accuracy:.3f}, \
loss: {loss: .3f}, \
lr : {optimizer.current_learning_rate}"
)
acc_vals.append(accuracy)
loss_vals.append(loss)
lr_vals.append(optimizer.current_learning_rate)
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dloss_dz)
activation1.backward(dense2.dloss_dinputs)
dense1.backward(activation1.dloss_dz)
# Update the weights and the biases
optimizer.pre_update_params()
optimizer.update_params(dense1)
optimizer.update_params(dense2)
optimizer.post_update_params()
return acc_vals, loss_vals, lr_valsacc_vals, loss_vals, lr_vals = train(decay=1e-3, momentum=0.5)epoch: 0, acc : 0.337, loss: 1.099, lr : 1.0
epoch: 1000, acc : 0.510, loss: 0.978, lr : 0.5002501250625312
epoch: 2000, acc : 0.557, loss: 0.879, lr : 0.33344448149383127
epoch: 3000, acc : 0.580, loss: 0.771, lr : 0.25006251562890724
epoch: 4000, acc : 0.630, loss: 0.735, lr : 0.2000400080016003
epoch: 5000, acc : 0.657, loss: 0.670, lr : 0.16669444907484582
epoch: 6000, acc : 0.753, loss: 0.573, lr : 0.1428775539362766
epoch: 7000, acc : 0.783, loss: 0.522, lr : 0.12501562695336915
epoch: 8000, acc : 0.790, loss: 0.481, lr : 0.11112345816201799
epoch: 9000, acc : 0.807, loss: 0.441, lr : 0.1000100010001
epoch: 10000, acc : 0.843, loss: 0.401, lr : 0.09091735612328393The model achieved the lowest loss and the highest accuracy that we’ve seen so far. Can we do better? Sure, we can! Let’s try to set the momentum to \(0.9\):
acc_vals, loss_vals, lr_vals = train(decay=1e-3, momentum=0.9)epoch: 0, acc : 0.340, loss: 1.099, lr : 1.0
epoch: 1000, acc : 0.763, loss: 0.463, lr : 0.5002501250625312
epoch: 2000, acc : 0.790, loss: 0.407, lr : 0.33344448149383127
epoch: 3000, acc : 0.803, loss: 0.396, lr : 0.25006251562890724
epoch: 4000, acc : 0.813, loss: 0.391, lr : 0.2000400080016003
epoch: 5000, acc : 0.813, loss: 0.386, lr : 0.16669444907484582
epoch: 6000, acc : 0.813, loss: 0.384, lr : 0.1428775539362766
epoch: 7000, acc : 0.813, loss: 0.375, lr : 0.12501562695336915
epoch: 8000, acc : 0.833, loss: 0.332, lr : 0.11112345816201799
epoch: 9000, acc : 0.880, loss: 0.285, lr : 0.1000100010001
epoch: 10000, acc : 0.880, loss: 0.277, lr : 0.09091735612328393AdaGrad
In real-world datasets, some input features are sparse and some features are dense. If we use the same learning rate \(\alpha\) for all the weights, parameters associated with sparse features receive meaningful updates only when these features occur. Given a decreasing learning rate, we might end up with a situation where parameters for dense features converge rather quickly to their optimal values, whereas for sparse features, we are still short of observing them sufficiently frequently before their optimal values can be determined. In other words, the learning rate decreases too slowly for dense features and too quickly for sparse features.
The update rule for adaptive step-size gradient descent is:
\[\begin{align*} \mathbf{g}_t &= \frac{\partial \mathcal L}{\partial \mathbf{w}}\\ \mathbf{s}_t &= \mathbf{s}_{t-1} + \mathbf{g}_{t}^2 \\ \mathbf{w}_t &= \mathbf{w}_{t-1} + \frac{\alpha}{\sqrt{\mathbf{s}_t+\epsilon}}\cdot \mathbf{g}_t \end{align*}\]
Here the operations are applied coordinate-wise. So, the jacobian \(\mathbf{g}_t^2\) has entries \(g_t^2\). As before, \(\alpha\) is the learning rate and \(\epsilon\) is an additive constant that ensures that we do not divide by \(0\). Thus, the learning rate for features whose weights receive frequent updates is decreased faster, whilst for those features, whose weights receive infrequent updates, it is decreased slower.
Thus, Adagrad decreases the learning-rate dynamically on a per-coordinate basis.
class AdagradOptimizer:
# Initial optimizer - set settings
# learning rate of 1. is default for this optimizer
def __init__(self, learning_rate=1.0, decay=0.0, epsilon=1e-7):
self.learning_rate = learning_rate
self.current_learning_rate = learning_rate
self.decay = decay
self.iterations = 0
self.epsilon = epsilon
# Call once before any parameter updates
def pre_update_params(self):
if self.decay:
self.current_learning_rate = self.learning_rate * (
1.0 / (1.0 + self.decay * self.iterations)
)
# Update parameters
def update_params(self, layer):
if not hasattr(layer, "weight_cache"):
layer.weight_cache = np.zeros_like(layer.weights)
layer.bias_cache = np.zeros_like(layer.biases)
# Update cache with squared current gradients
layer.weight_cache += layer.dloss_dweights**2
layer.bias_cache += layer.dloss_dbiases**2
# Vanilla SGD parameter update + normalization
# with square rooted cache
layer.weights += (
self.current_learning_rate
* layer.dloss_dweights
/ (np.sqrt(layer.weight_cache) + self.epsilon)
)
layer.biases += (
self.current_learning_rate
* layer.dloss_dbiases
/ (np.sqrt(layer.bias_cache) + self.epsilon)
)
def post_update_params(self):
self.iterations += 1RMSProp
One of the key issues of Adagrad is that the learning rate decreases at a predefined schedule essentially at a rate proportional \(\frac{1}{\sqrt{t}}\). While this is generally appropriate for convex problems, it might not be ideal for nonconvex ones, such as those encountered in deep learning. Yet, the coordinate-wise adaptivity of Adagrad is highly desirable as a preconditioner.
Tieleman and Hinton(2012) have proposed the RMSProp algorithm as a simple fix to decouple the rate scheduling from coordinate adaptive learning rates. The issue is that the squares of the gradient \(\mathbf{g}_t\) keeps accumulating into the state vector \(\mathbf{s}_t = \mathbf{s}_{t-1} + \mathbf{g}_t^2\). As a result, \(\mathbf{s}_t\) keeps on growing without bounds, essentially linearly as the algorithm converges.
The Algorithm
The update rule for the RMSProp algorithm is as follows:
\[\begin{align*} \mathbf{s}_t &= \gamma \mathbf{s}_{t-1} + (1- \gamma)\mathbf{g}_t^2\\ \mathbf{x}_t &= \mathbf{x}_{t-1} - \frac{\alpha}{\sqrt{\mathbf{s}_t + \epsilon}}\odot \mathbf{g}_t \end{align*}\]